Ultimamente ho avuto la necessita’ di rinominare una serie di file in bulk.
Tali files erano all’interno di una cartella, la quale veniva usata dal demone samba per la condivisione nella mia rete.
Il problema che avevo era dovuto al fatto che samba mal supporta i file con i nomi troppo lunghi e per tale motivo, se si accede da remoto alla cartella, vediamo una sequenza di caratteri “strani” invece del loro nome originale
Supponiamo di avere un file del genere nella cartella usata da samba
Dopo (tanti) anni di studio ed un lavoro (precario) credo sia arrivata finalmente l’ora di iscrivermi all’albo degli Ingegneri, ma prima di farlo ho cercato di fare una piccola statistica su quanti ingegneri c’erano nella mia provincia (Potenza) e a quale tipo di specializzazione appartenessero.
Purtroppo lo strumento di ricerca del sito ( http://www.ordingpz.it/albo/Albolist.asp ) mette a disposizione dell’utente poche opzioni di ricerca, per tale motivo ho rispolverato la cara e vecchia libreria python Beautiful Soup per scrivere un piccolo script python il quale mi aiutasse ad effettuare il parsing di più pagine HTML e tirasse fuori i dati che mi interessavano.
Il sito in questione (http://www.ordingpz.it) ha una pagina web per ogni ingegnere iscritto all’albo. Tale pagina contiene i vari dettagli dell’ utente, compreso il campi che a me interessavano: “Settore” e “Specializzazione“.
Al seguente link è possibile avere un esempio reale del dettaglio dell’utente (l’ingegnere non è stato scelto a casa, ma è un mio amico con cui ha avuto il piacere di lavorare assieme).
try:
data = urllib2.urlopen(url).read()
except:
print url
soup = BeautifulSoup(data)
n = soup.findAll(“td”,{“width”:”100″})
#print n
numIscr = []
for i in n:
numIscr.append(i.div.string)
A questo punto la lista numIscr contiene tutti gli ID dell’albo degli Ingegneri di Potenza, adesso non ci resta che accedere alle singole pagine degli user e memorizzare tutte le informazioni che ci servono.
Il ciclo for può esterno non va altro che prendere tutti gli ID contenuti in numIscr , accedere alla pagina dell’utente ad esso associato e tramite BeautifulSoup effettuare il parsing della pagina HTML per tirare fuori le informazioni.
Parse HTML
[sourcecode language=”python”]
for i in range(len(numIscr)):
url = “http://www.ordingpz.it/albo/Alboview.asp?N__ISCR_=”+str(numIscr[i])
f.write(url+”\n”)
print “Parsing “+ str(i) + ” of ” + str(len(numIscr))
print url
try:
data = urllib2.urlopen(url).read()
except:
print url
soup = BeautifulSoup(data)
#print soup.prettify()
n = soup.findAll(“td” , “ewTableHeader”)
fields = []
for i in n:
fields.append(i.string.encode(‘ascii’,’ignore’))
n = soup.findAll(“div”)
values = [];
#print n
count = 0;
for i in n:
count=count+1;
#print count
if(i.string != None and count > 19):
#print i.string
values.append(i.string.encode(‘ascii’,’ignore’))
for i in range(len(values)):
try:
f.write(str(fields[i]+ “: “+values[i]).encode(‘utf-8’)+”\n”)
except:
print fields[i]+ “: “+values[i]
f.write(“\n”)
f.close()
[/sourcecode]
Nella lista fields saranno elencati tutti i campo della tabella (Ex. Nome, Cognome, Specializzazione ecc) ed in quella values tutti i valori dei campi prima citati. Lo step successivo è quello di scrivere tutte queste informazioni in un unico file per poi poter fare tutte le nostre statistiche in maniera semplice ed immediata.
Il file IngPZAll.txt è output dello script, ed avrà al suo interno il dettaglio di tutti gli ingegneri iscritti all’albo.
Output Example
[sourcecode language=”text”]
..
..
..
http://www.ordingpz.it/albo/Alboview.asp?N__ISCR_=2714
N Iscrizione: 2714
Cognome: MONACO
Nome: Pierpaolo
Luogo di Nascita: Potenza
Data di Nascita:
C.F.:
Indirizzo:
CAP:
Citt:
Provincia: PZ
Sezione: A
Settore: Civile ed Ambientale, Industriale, Dell’Informazione
N Iscrizione: 2714
Data Iscrizione: 04/01/2012
Specializzazione: Informatica
Sede Laurea: Roma
Data Laurea: 21/03/2011
Sede Abilitazione: Roma
Anno Abilitazione: 2011
Ordine di Provenienza: Potenza
Data Prima Iscrizione: 04/01/2012
..
..
[/sourcecode]
Ora con una semplice comando bash posso facilmente capire ciò che volevo…
Ancora devo abituarmi all’idea di poter passare una domenica senza toccare un libro universitario. Quante ne ho passate cercando disperatamente di memorizzare e ripassare (in realtà rare volte sono arrivato alla fase di ripasso 😛 ) qualche argomento per gli esami sempre troppo vicini.
Era arrivata l’ora di riempire un pò questo blog, un blog nato come passatempo serale… e che ho lasciato nel dimenticatoio per troppo tempo.
Quale miglior argomento di un pò di codice assembly ARM e GPIO per ricominciare??
Lo scopo è quello riuscire ad accendere e spegnere un misero led (OK or ACT led per le specifiche Raspberry) collegato al 16esimo pin GPIO (pdf to ARM peripherals) tramite codice scritto direttamente in assembly.
1) Download e Settings ARM Toolchain
La prima cosa da fare è installare una toolchain di sviluppo per processori ARM. Se non volere compilarvi gcc a “manella” potete utilizzare questa toolchain pronta per l’uso ( disponibile per Windows/Linux/MacOS): YAGARTO
Una volta scaricato ed aperto il .dmg, vi chiederà di spostare il file .app in una cartella ed eseguirlo in modo tale da copiare i file binari di gcc in essa.
[sourcecode language=”bash”]unicondor@iMac:yagarto-4.7.2> ls
Binutils.webloc COPYING.LIBGLOSS COPYING3.LIB GNU.webloc arm-none-eabi lib source.txtCOPYING COPYING.NEWLIB GCC.webloc Newlib.webloc bin libexec tools
COPYING.LIB COPYING3 GDB.webloc YAGARTO.webloc include share version.txt
[/sourcecode]
Ora non ci resta altro che includere il percorso di tale cartella nella variabile locale relativo ai vari PATH della nostra shell.
Per facilitarci ancora di più il compito possiamo procurarci questo template. Composto da una serie di files (sotto elencati) che ci aiuteranno nella compilazione dei nostri sorgenti
Dove: main.s sarà il nostro file sorgenti scritto direttamente in assembly ARM kernel.ld è usato dal linker per mappare correttamente le zone di memoria (qualche interessante articolo si potrebbe scrivere su questo file) Makefile spero non ci sia bisogno di spiegazioni 😛
3) Main.s
Ecco il file più importante, il file sorgente scritto direttamente in ARM assembly
[sourcecode language=”bash”]
/*
* .section is a directive to our assembler telling it to place this code first.
* .globl is a directive to our assembler, that tells it to export this symbol
* to the elf file. Convention dictates that the symbol _start is used for the
* entry point, so this all has the net effect of setting the entry point here.
* Ultimately, this is useless as the elf itself is not used in the final
* result, and so the entry point really doesn’t matter, but it aids clarity,
* allows simulators to run the elf, and also stops us getting a linker warning
* about having no entry point.
*/
.section .init
.globl _start
_start:
/*
* This command loads the physical address of the GPIO region into r0.
*/
ldr r0,=0x20200000
/*
* Our register use is as follows:
* r0=0x20200000 the address of the GPIO region.
* r1=0x00040000 a number with bits 18-20 set to 001 to put into the GPIO
* function select to enable output to GPIO 16.
* then
* r1=0x00010000 a number with bit 16 high, so we can communicate with GPIO 16.
*/
mov r1,#1
lsl r1,#18
/*
* Set the GPIO function select.
*/
str r1,[r0,#4]
/*
* Set the 16th bit of r1.
*/
mov r1,#1
lsl r1,#16
/*
* Set GPIO 16 to low, causing the LED to turn on.
*/
str r1,[r0,#40]
/*
* Loop over this forevermore
*/
loop$:
b loop$
[/sourcecode]
Nella sezione references trovate altri esempi da cui questo è stato preso. E’ molto semplice ed intuitivo da capire, inoltre è anche ben commentato per cui posso evitare di spiegare cosa fa 😀
Non dobbiamo fare altro che aggiungere il main.s nella cartella source del template prima scaricato e lanciare la compilazione. Infine avremo il nostro bel kernel.img da poter inserire nella nostra scheda SD e rimpiazzarlo con quello ufficiale di Raspian.
Se tutto e’ andato nel verso giusto, appena inserita l’alimentazione al nostro raspberry si accendera’ il LED ACT…. forse 😛
Già mi ero cimentato qualche volta con la creazione di un video tramite sequenza di immagini timelapse, usando dei tool che in automatico mi creavano il flusso video da una sequenza di immagini.
Questa volta, da buon smanettone :P, ho voluto utilizzare solo la potenza della shell di Linux e strumenti OpenSource come ffmpeg.
L’hardware a disposizione non è stato uno dei migliori. Ho dovuto utilizzare il mio vecchio Asus EeePC 701 dotato di una misera telecamera da 640×480 px … e tanta pazienza :D.
1) Cattura Immagini Timelapse
Per la cattura delle immagini dalla videocamera ho usato il tool sviluppato da Ubuntu: cheese e l’utility scrot per quanto riguarda la cattura delle immagine tramite screenshot.
Il mio script non fa altro che lanciare cheese in background a tutto schermo e catturare le immagini ogni 5 sec via scrot. So che esistono molti altri metodi per catturare le immagini direttamente dalla fotocamera senza effettuare lo screenshot, ma nel mio caso avevo bisogno di mostrare anche al pubblico le immagini che stavo riprendendo.
[sourcecode language=”bash”]
#!/bin/sh
/usr/bin/cheese &
while true
do
scrot /media/photo/’%H%M%S.png’
sleep 5
done
[/sourcecode]
2) Creazione Flusso Video
Se tutto è andato nel verso giusto avremo le nostre .png pronte per essere unite tra loro per creare il flusso video vero e proprio. FFMPEG è proprio il tool che fa a caso nostro, infatti basta dare questo piccolissimo comando per avere il video finale.
Dovrei studiare per l’esame di stato ma, ogni giorno, trovo sempre qualcosa di piu’ interessante da fare.
Era da un po’ di tempo che avevo in mente l’idea di creare degli HotSpot WiFi Free per l’accesso gratuito ad Internet per i clienti di: Caffe del Corso e Bar Belvedere (permettetemi un po’ di pubblicita’ 😛 ).
Dopo aver girovagato un po’ su internet sulle varie soluzioni da poter utilizzare, alla fine il suggerimento migliore (come sempre accade) e’ stato quello del mio mentore Franco 😀
Utilizzare pfsense come Captive Portal e’ davvero semplice ed intuitivo. Ci ho perso solo 2 gg 😛 , ma questo mi ha permesso di avere degli accessi controllati sia in termini di banda (download/upload) sia in termini di tempo (minuti per ogni connessione).
Ho usato una macchina virtuale tramite Virtualbox per far girare pfsense (Attenzione, quando create la macchina virtuale scegliete BSD e non Linux altrimenti non vi vede le interfacce di rete ). Di seguito vi mostro i passi da seguire per un corretto settaggio delle interfacce di rete e del Captive Portal.
Per l’installazione di pfsense su macchine virtuali trovate un sacco di tutorial su google, io ho scaricato direttamente la .iso image del LiveCD montata all’avvio e poi ho provvedo alla sua installazione sull’hard disk virtuale.
Premetto che da buon utilizzare di Slackware, ho utilizzato l’interfaccia testuale e non quella grafica. Il risultato finale è lo stesso, una volta capito cosa fare potete impostare i miei stessi parametri utilizzando la comoda interfaccia web che pfsense ci mette a disposizione.
Appena finita l’installazione di pfsense, ho settato la prima interfaccia virtuale in bridge mode con la mia interfaccia fisica WAN, e la seconda interfaccia virtuale in bridge mode con la mia ethernet che fungera’ da LAN interna per l’HotSpot.
Wan InterfaceLAN Interface
1) Riepilogo Interfacce e Creazione VLANs
Al primo avvio di pfsense avremo il riepilogo delle interfacce che abbiamo a disposizione, rispettivamente: em0 ed em1 (quelle settate nelle figure precedenti), e la richiesta di creare delle interfacce vortuali all’interno di pfsense. Per ora scriviamo “n”, possiamo abilitare le interfacce viartuali in un secondo momento.
I problemi erano gia’ parecchi prima di iniziare la tesi, ma ora credo di aver passato ogni limite. Non posso passare le nottate appresso ad una board con 48K di RAM, 256KB di Flash ed un processore ARM Cortex-M a 78 Mhz preso da una insana, quanto assurda, smania verso ogni tipo di controllore per montarci su un RTOS 😛
La board in questione mi e’ stata gentilmente concessa dal mio Professore, per giunta lo stesso professore relatore della mia tesi. Per tale motivo, credo di aver una scusa decente per essere un po’ in ritardo nella stesura :P.
Il programma di esempio su cui mi sono cimentato utilizza un RTOS ( ChibiOS/RT ) e la sua toolchain (davvero semplicissima da usare grazie alla sua integrazione con Eclipse) usata per compilare il file oggetto e caricarlo direttamente in flash.
Una passeggiata rispetto a quello fatto per il porting di ThreadX su un microcontrollore ARC-based, ma questo (forse) sara’ un articolo che cerchero’ di scrivere un po’ piu’ il la… sempre che il lavoro svolto sia sufficientemente decente.
Ritornando all’applicazione, e’ davvero un programmino semplice che emula il comportamento del famoso gioco della fortune wheel (non sono sicuro del nome 😛 ) ed e’ composto da tre threads:
main
thread1
thread2
Dove il main si occupara di gestire un interrupt che gli arriva quando premiamo il pulsante USER; thread1 non e’ altro che un semplice ciclo while che accende e spegne, in maniera circolare, gli 8 LED; il thread2 che si occupa di verificare se nell’attimo in cui e’ stato premuto il pulsante USER la luce del LED rosso era accesa…. vabbe’ e’ piu’ semplice a farsi che a dirsi.
/*
* This is a periodic thread that does absolutely nothing except flashing LEDs.
*/
static WORKING_AREA(waThread1, 128);
static msg_t Thread1(void *arg) {
(void)arg;
chRegSetThreadName("blinker");
int i=0;
int ledTime[10]={215,260,220,600,40,20,10,5,15,25};
while (TRUE) {
/*
* System initializations.
* – HAL initialization, this also initializes the configured device drivers
* and performs the board-specific initializations.
* – Kernel initialization, the main() function becomes a thread and the
* RTOS is active.
*/
//palSetPad(GPIOE, GPIOE_LED3_RED);
halInit();
chSysInit();
//palSetPad(GPIOE, GPIOE_LED3_RED);
/*
* Activates the serial driver 1 using the driver default configuration.
* PA9(TX) and PA10(RX) are routed to USART1.
*/
sdStart(&SD1, NULL);
palSetPadMode(GPIOA, 9, PAL_MODE_ALTERNATE(7));
palSetPadMode(GPIOA, 10, PAL_MODE_ALTERNATE(7));
//palSetPad(GPIOE, GPIOE_LED3_RED);
/*
* Creates the example thread.
*/
chThdCreateStatic(waThread1, sizeof(waThread1), NORMALPRIO, Thread1, NULL);
//palSetPad(GPIOE, GPIOE_LED3_RED);
/*
* Normal main() thread activity, in this demo it does nothing except
* sleeping in a loop and check the button state, when the button is
* pressed the test procedure is launched.
*/
while (TRUE) {
if (palReadPad(GPIOA, GPIOA_BUTTON)){
chThdCreateStatic(waThread2, sizeof(waThread2), NORMALPRIO, Thread2, NULL);
chThdSleepMilliseconds(500);
}
}
}
Posso staccare la penna USB senza forzare la rimozione?
Quante volte ho sentito questa domanda, la maggior parte della gente toglie la propria penna USB dal pc senza “smontarla” secondo la procedura, sicuri che non si danneggi nulla. Ma e’ davvero “sicuro” farlo??
Bhe se avete un pc con Windows 7 e versioni successive, e’ abbastanza sicuro. Windows disabilita il write caching sulle periferiche che riconosce come removable , consapevoli del fatto che la maggior parte dei sui utilizzatori non smonta mai il proprio device USB.
A questo punto, se sei arrivato a leggere fino a qui e non sei uno esperto/smanettone ti sarai chiesto: Ma cosa e’ il write-caching?
E’ la policy che utilizza la maggior parte dei Sistemi Operativi quando si deve scrivere un dato in una memoria dati esterna, magari collegata tramite USB. Tramite tale tecnica, non vengono copiati immediatamente i dati dal vostro pc sulla memoria (soprattutto se sono dati di piccoli dimensioni), ma vengono messe in una cache in attesa che ci siano altri dati da scrivere in modo da aumentare le performance. Infatti, la scrittura sui device esterni avviene molto piu’ velocemente per file di dimensioni grandi e non con file piccoli.
Per tale motivo, molti Sistemi Operativi la adottano; per aumentare le performance… costringendoci a “smontare” la chiavetta e “forzare” la scrittura dei dati che sono ancora in cache.
Mac OS X adotta la stessa politica di Windows?
Bhe se avete un Mac, vi tocca smontarla. Infatti il Sistema Operativo di casa Cupertino, non disabilita il write-caching come Windows.
Ma è possibile forzare in qualche modo tale policy e dire a Mac OS X di non usare il write-caching. Come farlo?
Il miglior modo per farlo è con il comando mount tramite la shell dei comandi:
[sourcecode language=”bash”]
mount -o noasync /dev/diskls1
[/sourcecode]
Dove diskls1 è il nome del device che vogliamo montare.
Il comando vale anche per molte distribuzioni Linux.
Ora potete rimuovere la vostra penna USB senza doverla smontare 😀
Quest’anno sono riuscito a partecipare (me ne sono ricordato :P) all’Hacker Cup che Facebook organizza ogni anno. I problemi per le qualificazioni erano 3 e di seguito vi posto le mie soluzioni scritte in python.
Il terzo problema (Find the min) non e’ difficile, sono riuscito a risolverlo ma il tempo che ci impiega il mio algoritmo e’ molto al di sopra di quello che mette a disposizione Facebook. In realta’ bastava guardare un po output della lista che utilizzavo per memorizzare i valori per capire che da un certo punto in poi si ripeteva ( per cui non serviva tutta la potenza di calcolo che avevo immaginato 😛 ). In poche parole per gli indici della liste pari a 2k+1, i valori si ripetevano… me ne sono accorto troppo tardi ed ho finito solo i primi due step 😀
values=[]
num=26
find=1
numSum=0
for k in range(0,len(i)):
#d[str(i[k])] = i.count(i[k])
if(str(i[k]).isalpha()):# or str(i[k])==’!’):
d[str(i[k])] = i.count(i[k])
for k in range(0,len(i)):
if (str(i[k]) in d):
# print i[k] + " num "+ str(num) + " # " + str(d[i[k]])
numSum += num*d[i[k]]
values.append(d[i[k]])
del d[i[k]]
num -=1
values_sorted= sorted(values, reverse=True)
num=26
numSum =0
for item in range(len(values_sorted)):
numSum += num * values_sorted[item]
num -=1
print "Case #" + str(flavio)+ ": " +str(numSum)
flavio +=1
[/sourcecode]
def isBalanced(strInput):
"""Validate if an input string is having balanced bracket pairs
this includes bracket ordering. i.e a round bracket must be closed
by a round bracket. Emtpy strings are treated as balanced."""
#if strInput:
# list of all bracket kinds, in paired tuples
brackets = [ (‘(‘,’)’), (‘[‘,’]’), (‘{‘,’}’)]
# define fake constants – python does not support the concept of constants
kStart = 0
kEnd = 1
# internal stack used to push and pop brakets in the input string
stack = []
for char in strInput:
for bracketPair in brackets:
if char == bracketPair[kStart]:
stack.append(char)
elif char == bracketPair[kEnd] and len(stack) > 0 and stack.pop() != bracketPair[kStart]:
return False
if len(stack) == 0:
return True
#return False
flavio=1
for i in range(0,len(b)) :
if(isBalanced(b[i])):
print "Case #" + str(flavio) + ": YES"
else:
print "Case #" + str(flavio) + ": NO"
def next(ary, start):
j = start
l = len(ary)
ret = start – 1
while j < l and ary[j]:
ret = j
j += 1
return ret
for t in range(T):
n, k = map(int, f.readline().strip().split(‘ ‘))
a, b, c, r = map(int, f.readline().strip().split(‘ ‘))
m = [0] * (4 * k)
s = [0] * (k+1)
m[0] = a
if m[0] <= k:
s[m[0]] = 1
for i in xrange(1, k):
m[i] = (b * m[i-1] + c) % r
if m[i] < k+1:
s[m[i]] += 1
p = next(s, 0)
m[k] = p + 1
p = next(s, p+2)
for i in xrange(k+1, n):
if m[i-k-1] > p or s[m[i-k-1]] > 1:
m[i] = p + 1
if m[i-k-1] <= k:
s[m[i-k-1]] -= 1
s[m[i]] += 1
p = next(s, p+2)
else:
m[i] = m[i-k-1]
if p == k:
break
Devo ammettere che l’argomento di tesi che mi tocchera’ svolgere mi appassiona sempre piu’. Questo piccolo articolo ne e’ la dimostrazione ( spero di poterlo ri-utilizzare almeno in un paragrafo 😛 ).
La tesi sara’ una di quelle Top-Secret, rivoluzionarie e che cambieranno la concezione del mondo… vabbe’ lasciatemi delirare un po’ 😀
Lo scopo avra’ come obiettivo quello di rimpiazzare il firmware (un ciclo while backend/frontend) di gestione di una memoria con un RTOS capace di gestire in maniera piu’ rigorosa ed attenta il multi-threading e gli eventi asincroni.
La scelta, per quando riguarda RTOS, credo che ricadra’ su ThreadX. Dalla lettura delle sue specifiche e guardando le sue features, sono giunto alla conclusione che sia la scelta migliore e per tale motivo ho focalizzato la mia analisi su due punti:
Gestione delle interruzioni ottimizzata per i processori ARM
Scheduler Preemption-Threshold
La maggior parte dei processori ARM supporta sia IRQ che FIQ come input interrups. FIQ viene definito come “fast” interrupt, mentre IRQ come “normal” interrupt. Entrambe le modalita’ di esecuzione hanno dei livelli di priorita’, e la modalita’ FIQ ha un livello piu’ alto rispetto a IRQ, per tale motivo se stiamo gestendo una interruzione con FIQ, essa non potra’ essere sospesa da un’altra interruzione arrivata sul canale IRQ.
Ma non e’ la sola differenza, ne esistono altre e sono molto piu’ sostanziali, rispetto alla precedente, sia a livello di architettura che a quello di gestione.
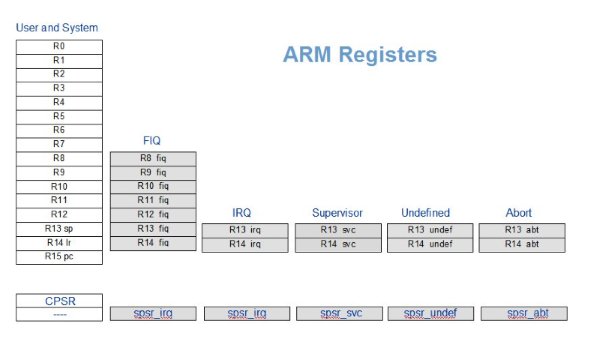
La prima sostanziale differenza e’ che la modalita’ FIQ ha dei registri in piu (7 registri in piu’ da R8-R14) mentre IRQ ne gestisce solo due ( vedi immagine successiva ), grazie ai quali si riduce l’overhead necessario alla copia dei valori di backup del processo precedente all’arrivo dell’interruzione. Per tale motivo, meno valori vengono spostati sullo stack e meno valori dovranno essere ripristinati nei registri alla fine delle gestione dell’interruzione. Il registro R14 viene usato come indirizzo di ritorno del PC(+4).
Il secondo motivo per cui FIQ e’ piu’ veloce rispetto a IRQ e’ dovuto alla posizione della gestione degli interrupts all’interno del vettore delle interruzioni, il codice di gestione degli interrups FIQ e’ situato alla fine di tale vettore (0x1C). Questo fa in modo che le istruzioni possono essere eseguite direttamente da tale locazione (dato che lo stack cresce per l’alto), senza effettuare ulteriori jump ad indirizzi di memoria (cosa non vera per le interruzioni IRQ).
Ad oggi, non molti RTOS e non supportano tale gestione delle interrups per un motivo semplice. La gestione delle interruzioni con FIQ puo’ essere effettuato solo scrivendo a “manella” il codice assembly.
Scrivere in C tale gestione non e’ sempre possibile, in quanto il compilatore utilizza i registri R0-R3 e non fornisce la corretta gestione del CSPR alla fine della funzione
Chiunque abbia fatto un minimo di parsing HTML tramite Python, ha incontrato almeno una volta questo fatidico errore (almeno lo spero, altrimenti sono l’unico pseudo smanettone ad averlo avuto 😛 ), soprattutto se il parsing e’ stato effettuato su pagine web in cui la valuta e’ l’Euro, dato che \u20ac rappresenta il simbolo “€” (dannato Euro, anche nel mondo dell’informatica ci da’ problemi).
Il problema deriva avviene quando Python cerca di codificare il simbolo € con un carattere ASCII.
Codifica?? Uhm?? se sei confuso come me… continua a leggere 😀
Prima di continuare facciamo un piccolo ricapitolazione di “Fondamento di Informatica”…la cosa piu’ importante da sapere e’ che: l’oggetto str in Python memorizza il suo valore come bytes, cioe’ con una sequenza di 8-bit, a.k.a string. Per questo motivo ogni carattere ASCII viene codificato in 8-bit, questo vuol dire che abbiamo a disposizione 0-255 rappresentazioni diverse… ma questo non e’ sufficiente per rappresentare i caratteri Russi, Arabi, Giapponessi… ed il nostro famoso simbolo dell’euro.
Per superare questa limitazione, Python usa unicode che memorizza il carattere con 16-bit o 32-bit dandoci la possibilita’ di rappresentare qualsiasi simbolo in qualsiasi linguaggio.
Voi direste.. Evviva! basta usare l’unicode e risolvo il problema, giusto? NO, non puoi…. ci mancherebbe che il mondo dell’informatica sia cosi’ logico e “clean” 😀
In particolare, non si puo scrivere su un file usando l’unicode, perche’ il file vuole una stringa che sia rappresentata da 8-bit. Dato che Python e’ molto “smart” cerchera’ in automatico di codificare/uniformare il carattere in unicode per la scrittura su file (o qualsiasi altro stream, come la shell), ma ahime’ c’e’ un problema… vediamo meglio con un esempio.
[sourcecode language=”python”]
>>> price_info = u’the price is \u20ac 5′
>>> type(price_info)
<type ‘unicode’>
>>> f = open(‘priceinfo.txt’,’wb’)
>>> f.write(price_info)
Traceback (most recent call last):
File "", line 1, in ?
UnicodeEncodeError: ‘ascii’ codec can’t encode character u’\u20ac’ in position 9: ordinal not in range(128)
>>>
[/sourcecode]
What happened?? Quando Python cerca di scrivere nel file “the price is € 5”, egli cerca di trasformare il valore unicode ‘\u20ac‘ in un carattere ASCII ad 8-bit… ma prima abbiamo detto che ASCII non contiene il carattere in questione… per cui… mi stai seguendo?? 😀
La soluzione e’ semplice (dopo che ho passato almeno una nottata su stackoverflow 😛 ):
Semplice!! abbiamo codificato l’unicode tramite ‘utf-8’, il quale usa una sequenza di 3 caratteri ‘\xe2\x82\xac‘ per rappresentare il simbolo dell’Euro , in questo modo possiamo passare facilmente da ‘utf-8′ ad ASCII.
Ovviamente nel caso volessimo leggere il simbolo al contrario ( cioe’ vedere sullo schermo il simbolo dell’euro) dovremmo procedere con la decodifica dei tre caratteri in ‘utf-8′ e poi effettuare il print 😉
Ma c’e’ davvero gente che legge i miei post??? Mmmm ne dubito… ma come sempre, questo post mi servira’ da qui ad una settimana, visto che la mia memoria e’ scarsa e mi capitera’ di nuovo di imbattermi in questo problema… spero almeno di ricordarmi di aver scritto qualcosa sull’argomento 😛